%%html
<script src="https://bits.csb.pitt.edu/preamble.js"></script>
%%html
<div id="mlalive" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
jQuery('#mlalive').asker({
id: "mlalive",
question: "How many bits are in a byte?",
answers: ["1","2","4","8","16","32"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Outline¶
- Some thoughts on the course title
- The memory hierarchy
- mmap
- Basics of parallel programming
- Shared memory vs message passing
- Basics of networking
- Distributed systems
Scalable Machine Learning for Big Data Biology¶
What is "big data"?
Big data has some or all of these properties:
- Volume The size of the data
- Velocity How quickly the data is generated
- Variety Data may be heterogeneous or come from different sources
- Veracity The quality of the data
Big data is a term for data sets that are so large or complex that traditional data processing applications are inadequate. Challenges include analysis, capture, data curation, search, sharing, storage, transfer, visualization, querying, updating and information privacy.
--Wikipedia
Your data is "big" if you can't productively analyze it on a single workstation.
--David Koes
Scalable Machine Learning for Big Data Biology¶
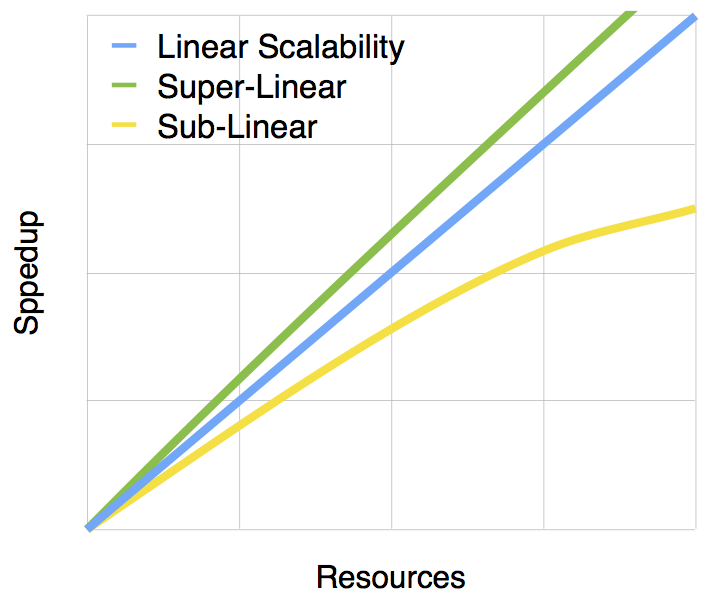
Scalability - how system performance increases as more resources are added
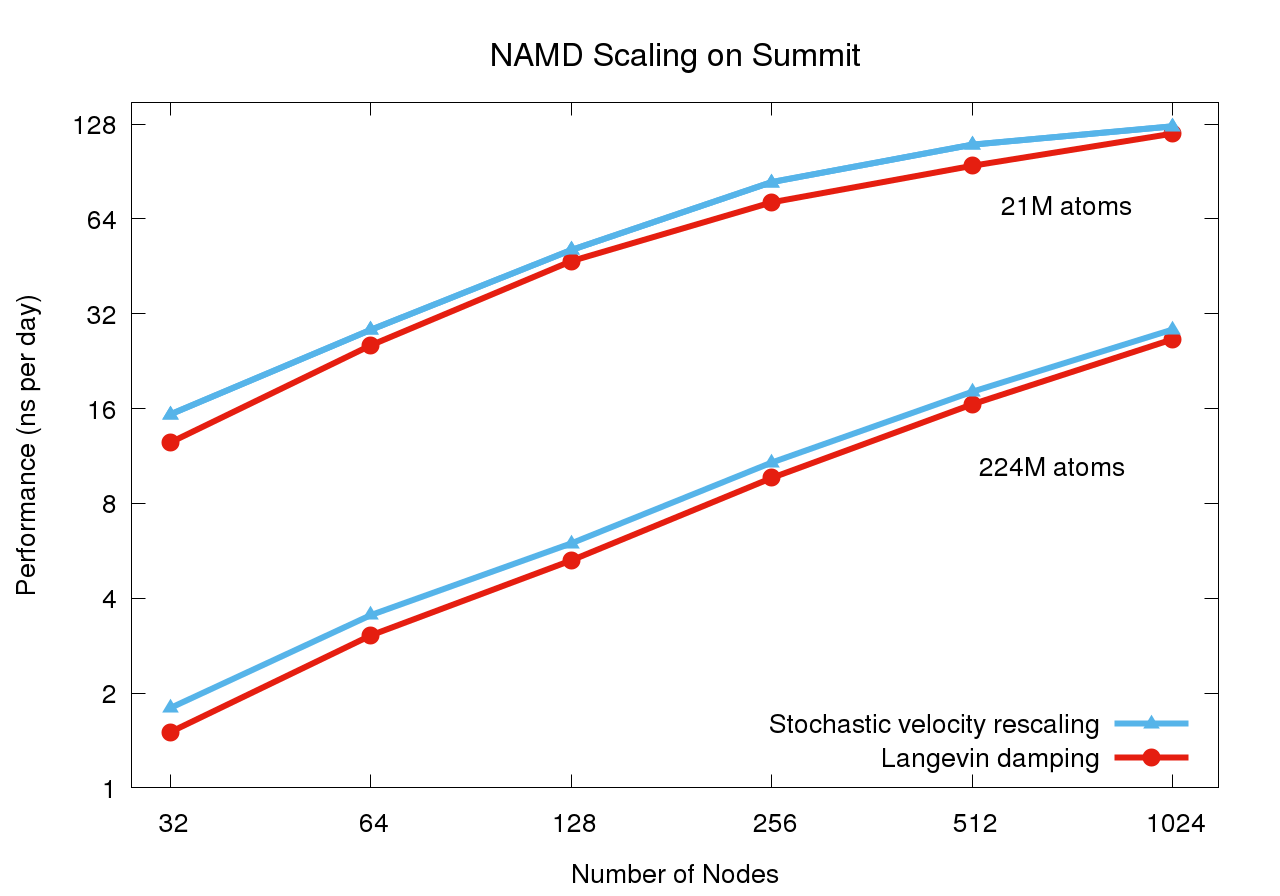
namd performance¶
%%html
<div id="mlscaling" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
jQuery('#mlscaling').asker({
id: "mlscaling",
question: "What kind of scaling is exhibited on the previous slide for 21M atoms?",
answers: ["Sub-linear","Linear","Super-linear"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Scalability¶
Factors that reduce scalability
- overhead of dividing work
- uneven division of work
- communication overhead
- contention for shared resources
- poor locality
Factors that can result in super-linear scaling
- reduced contention
- improved locality
Assembly¶
0f b6 45 20 movzbl 0x20(%rbp),%eax
89 c1 mov %eax,%ecx
c0 e9 02 shr $0x2,%cl
83 e1 07 and $0x7,%ecx
48 0f af 4d 10 imul 0x10(%rbp),%rcx

Memory Access Times¶
- L1 Cache 1-2ns
- L2 Cache 3-5ns
- L3 Cache 12-20ns
- DRAM 60-200ns
Memory througput (sequential): 8-400 GB/s (GPUs even higher)

Disk Access Time¶
Seek time: 8-12ms
Sequential read throughput: ~50-300MB/s
Random read throughput: < 1MB/s
Cost: \$0.01/GB - $0.10/GB

SSD Access Time¶
Access time: 5-50$\mu$s
Sequential read throughput: 500 - 3500MB/s
Random read throughput: 25-50MB/s (but improves 10-20X if requests done simultaneously)
Cost: \$0.15/GB - $0.30/GB

%%html
<div id="mlaccess" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
jQuery('#mlaccess').asker({
id: "mlaccess",
question: "How much faster is it to access memory than disk?",
answers: ["100X","1,000X","10,000X","100,000X","1,000,000X"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
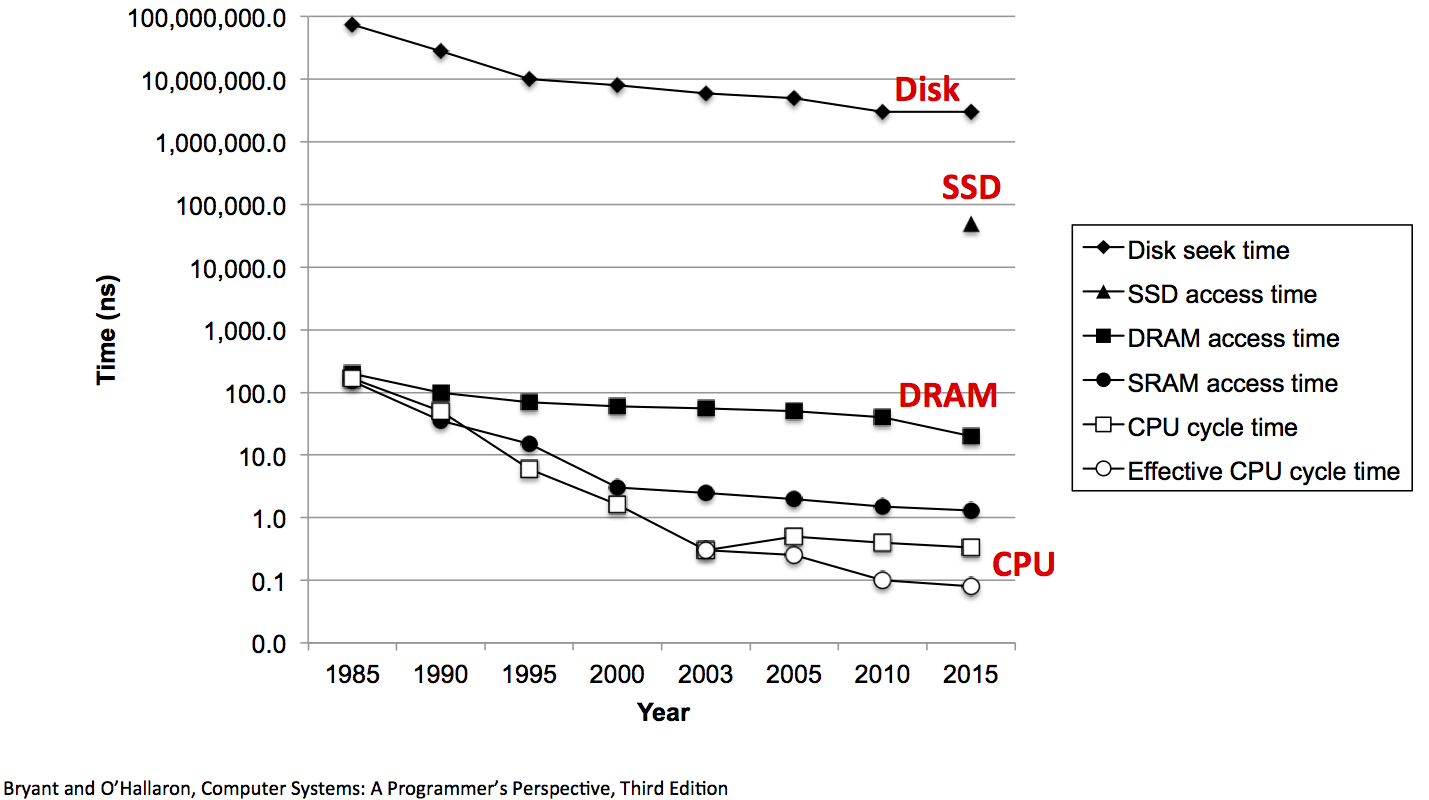
Takeaways¶
Disks are slow compared to memory. Really slow (even SSDs)
But they are still the most cost effective means of storing large datasets
Memory hierarchies use caching* to exploit locality and provide high-speed access to large datasets.*
Spatial Locality¶
Referencing items that are stored nearby in memory
memory caches load an entire cache line (typically 64 bytes) - accessing arr[i] will likely pull arr[i+1] into the cache
file caches load an entire page (typically 4096 bytes) and often prefetch additional pages
Temporal Locality¶
Referencing the same item over and over again
- stays in cache, only the first reference is an expensive cache miss to memory/disk (unless there is spatial locality as well)
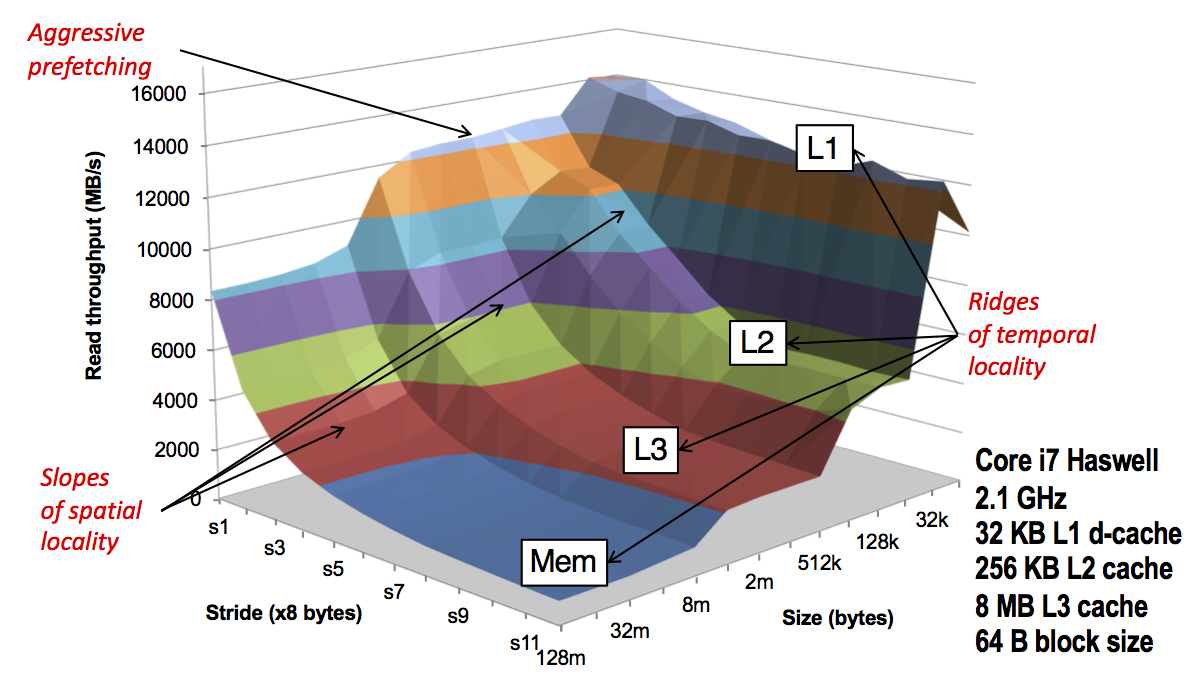
How can exploiting locality result in super-linear scaling?¶
e.g., code runs 105X faster on 100 machines than on 1 machine
Parallel Programming¶
There are several parallel programming models enabled by a variety of hardware (multicore, cloud computing, supercomputers, GPU).

Threads vs. Processes¶
A thread of execution is the smallest sequence of programmed instructions that can be managed independently by an operating system scheduler.
A process is an instance of a computer program.

Address Spaces¶
A process has its own address space. An address space is a mapping of virtual memory addresses to physical memory addresses managed by the operating system.
Address spaces prevent processes from crashing other applications or the operating system - they can only access their own memory.

Memory Mapping¶
Multiple virtual addresses can map to the same physical address. This is especially useful for read-only data.
Virtual addresses need not map to physical addresses - they can also be placeholders to indicate the data is stored elsewhere.
Swapping The operating system can move data from memory to disk (swap it out) if it needs more memory. When the corresponding virtual address is accessed a page fault occurs and the data is loaded back from disk into memory.
We can specify a mapping from memory to a file with mmap
mmap¶
mmap takes a file descriptor and returns an interface that can be read/written as a file or as an array.
Data is not transfered from disk to memory until it is accessed. This memory is part of the operating systems file cache.
Files can be mmapped with different access settings that change how data is stored and swapped.
- ACCESS_READ If data is read-only, operating system does not have to write the data back to disk when needs to swap it out for more memory. Also, different processes mapping the same file will use the same physical memory.
- ACCESS_WRITE Write-through behavior (changes appear in file - eventually). Basically gives you an array interface to file system data. Other processes mapping the file will see changes.
- ACCESS_COPY Any changes (writes) are only visible to this process.
mmap¶
import mmap
help(mmap.mmap)
Help on class mmap in module mmap: class mmap(builtins.object) | Windows: mmap(fileno, length[, tagname[, access[, offset]]]) | | Maps length bytes from the file specified by the file handle fileno, | and returns a mmap object. If length is larger than the current size | of the file, the file is extended to contain length bytes. If length | is 0, the maximum length of the map is the current size of the file, | except that if the file is empty Windows raises an exception (you cannot | create an empty mapping on Windows). | | Unix: mmap(fileno, length[, flags[, prot[, access[, offset]]]]) | | Maps length bytes from the file specified by the file descriptor fileno, | and returns a mmap object. If length is 0, the maximum length of the map | will be the current size of the file when mmap is called. | flags specifies the nature of the mapping. MAP_PRIVATE creates a | private copy-on-write mapping, so changes to the contents of the mmap | object will be private to this process, and MAP_SHARED creates a mapping | that's shared with all other processes mapping the same areas of the file. | The default value is MAP_SHARED. | | To map anonymous memory, pass -1 as the fileno (both versions). | | Methods defined here: | | __delitem__(self, key, /) | Delete self[key]. | | __enter__(...) | | __exit__(...) | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __len__(self, /) | Return len(self). | | __repr__(self, /) | Return repr(self). | | __setitem__(self, key, value, /) | Set self[key] to value. | | close(...) | | find(...) | | flush(...) | | madvise(...) | | move(...) | | read(...) | | read_byte(...) | | readline(...) | | resize(...) | | rfind(...) | | seek(...) | | size(...) | | tell(...) | | write(...) | | write_byte(...) | | ---------------------------------------------------------------------- | Static methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | closed
mmap¶
f = open('bcsmall.csv')
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
mm[:5]
b'age,a'
mm.readline()
b'age,alive,ABCA10,ABCA13,ABCA8,ABR,ADAMTS12,ADAMTS20,ADAMTSL1,ADCY9,AFF2,AHCTF1,AHNAK,AHNAK2,AIM1,AKAP13,AKAP6,AKAP9,AKD1,ALMS1,ANK1,ANK2,ANK3,ANKHD1,ANKRD11,ANKRD12,ANKRD17,ANKRD30BL,APC,APOB,APOBR,ARFGEF1,ARHGAP29,ARID1A,ARID1B,ASH1L,ASPM,ASTN1,ASXL2,ATM,ATN1,ATP10A,ATP10B,ATP11A,ATP1A4,ATP2B1,ATP7A,ATR,ATRX,ATXN2,BAZ2B,BCORL1,BIRC6,BPTF,BRCA2,BRWD1,BRWD3,C10orf12,C1orf173,C2orf16,C5orf42,C9orf174,CACNA1A,CACNA1B,CACNA1C,CACNA1D,CACNA1E,CACNA1F,CAD,CADPS,CAMTA2,CASP8AP2,CASZ1,CBFB,CBLB,CCDC144A,CCDC88A,CD163L1,CDC42BPA,CDH1,CDK12,CECR2,CENPE,CEP350,CFH,CFTR,CHD3,CHD4,CHD5,CHD6,CHD7,CHD8,CHD9,CIT,CMYA5,CNOT1,CNOT3,CNTLN,CNTNAP2,CNTNAP5,CNTRL,COL12A1,COL14A1,COL6A3,COL6A5,COL6A6,COL7A1,CPAMD8,CR1,CREBBP,CRNKL1,CROCCP2,CSMD1,CSMD2,CSMD3,CSPP1,CTCF,CTNNA2,CUBN,DCC,DCHS1,DCHS2,DIP2A,DLC1,DMD,DMXL1,DMXL2,DNAH1,DNAH10,DNAH11,DNAH12,DNAH14,DNAH17,DNAH2,DNAH3,DNAH5,DNAH6,DNAH7,DNAH8,DNAH9,DNAJC13,DNHD1,DNM1P46,DOCK10,DOCK11,DOCK4,DOCK7,DOCK9,DSE,DSP,DST,DYNC1H1,DYNC2H1,DYSF,EML6,EP400,ERBB2,ERBB3,ERCC6,EYS,F5,F8,FAM123B,FAM157B,FAM186A,FAM208B,FAM47C,FAM5C,FAM75D1,FAM75D5,FAT1,FAT2,FAT3,FAT4,FBN1,FBN3,FCGBP,FER1L6,FHOD3,FLG,FLG2,FLNA,FLNB,FLNC,FMN2,FNDC1,FOXA1,FRAS1,FREM1,FREM2,FREM3,FRG1B,FRMPD4,FRYL,GATA3,GCC2,GCN1L1,GLI2,GOLGA6L2,GOLGB1,GON4L,GPR112,GPR125,GPR98,GREB1L,GRIA3,GRID1,GRIK2,GRIN2A,GRIN2B,GTF3C1,HCFC1,HDAC6,HDX,HEATR7B2,HECTD4,HECW1,HECW2,HEG1,HERC1,HERC2,HMCN1,HRNR,HS6ST1,HSPG2,HUWE1,HYDIN,IGSF10,ITPR1,ITPR2,ITPR3,ITSN2,KALRN,KAT6B,KCNT2,KDM2A,KDM6A,KIAA0232,KIAA0913,KIAA0947,KIAA1109,KIAA1210,KIAA1239,KIAA1731,KIAA2022,KIF1B,KIF21B,KIF26B,KIF4A,LAMA1,LAMA3,LAMB4,LCT,LPA,LRBA,LRP1,LRP1B,LRP2,LRP4,LRRC41,LRRIQ1,LTBP2,LYST,MACF1,MAGI1,MALAT1,MAP1A,MAP2,MAP2K4,MAP3K1,MAST1,MDN1,MED12,MED13L,MEGF8,MGA,MGAM,MKI67,MLL,MLL2,MLL3,MLL4,MLLT4,MPDZ,MST1P9,MTM1,MTOR,MUC12,MUC16,MUC17,MUC2,MUC20,MUC4,MUC5B,MUC6,MXRA5,MYB,MYCBP2,MYH1,MYH10,MYH11,MYH14,MYH6,MYH7,MYH8,MYH9,MYO18B,MYO5B,MYO7A,MYO9A,MYOF,MYT1L,NALCN,NAV3,NBAS,NBEA,NBEAL1,NBEAL2,NBPF1,NBPF10,NCOR1,NEB,NF1,NHS,NID1,NIN,NIPBL,NLGN3,NLRC5,NOTCH2,NRXN2,NRXN3,NUP160,NXF1,OBSCN,ODZ1,ODZ3,ODZ4,OTOF,OTOGL,PAPPA2,PCDH10,PCDH11X,PCDH15,PCDH19,PCDHGB6,PCLO,PCNT,PCNXL2,PDE4DIP,PDZD2,PEG3,PHKA2,PIEZO1,PIK3CA,PIK3R1,PIWIL1,PKD1L1,PKD1L2,PKHD1,PKHD1L1,PLCB4,PLCE1,PLEKHG2,PLXNA2,PLXNA4,POM121,PREX2,PRKDC,PRPF8,PRRC2B,PRRC2C,PRUNE2,PTEN,PTPN13,PTPRB,PTPRD,PXDNL,QSER1,RAPGEF6,RB1,RBMX,RELN,REV3L,RGAG1,RGPD3,RIF1,RIPK1,RLF,RNA5-8SP6,RNF213,RP1,RPGR,RTL1,RUNX1,RYR1,RYR2,RYR3,SACS,SAGE1,SCN10A,SCN11A,SCN1A,SCN2A,SCN3A,SCN5A,SCN7A,SCN8A,SDK1,SDK2,SEPT10,SETD2,SETDB1,SETX,SF3B1,SH3PXD2A,SHANK2,SHROOM2,SI,SLC12A5,SMG1,SPAG17,SPEN,SPHKAP,SPTA1,SPTB,SRCAP,SRGAP2,SRRM2,SSPO,STAG2,STARD9,STK31,SUPT5H,SUPT6H,SVEP1,SVIL,SYNE1,SYNE2,TAF1,TAF1L,TANC2,TBC1D4,TBX3,TCF20,TCHH,TEP1,TEX15,TG,THSD7A,THSD7B,TLN1,TLN2,TLR4,TMEM132D,TNRC18,TNRC6A,TNRC6B,TNXB,TP53,TP53BP1,TPR,TRIO,TRPM6,TRRAP,TTN,UBE4B,UBR4,UBR5,UNC13C,UNC5D,UNC79,USH2A,USP34,USP9X,UTRN,VCAN,VPS13A,VPS13B,VPS13C,VPS13D,VWA3A,WDFY3,WDFY4,WDR52,WNK1,WNK3,XIRP2,YLPM1,ZAN,ZDBF2,ZFHX3,ZFHX4,ZFP106,ZFP64,ZMYM3,ZNF462,ZP4,ZZEF1\n'
mm[:5]
b'age,a'
mm[0] = 0
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) /var/folders/c_/pwm7n7_174724g8zkkqlpr3m0000gn/T/ipykernel_90836/2602634621.py in <module> ----> 1 mm[0] = 0 TypeError: mmap can't modify a readonly memory map.
mm[0]
97
When mmap can provide performance benefit¶
- Your data can be stored in a single local file
- Your data is read only
- The size of the data does not fit comfortably in memory or N processes will use the same data and N copies does not fit comfortably in memory
- You need to read the data more than once
- If only need to read once, optimize for sequential access and stream it
- Data is not accessed sequentially
- Your code will run on machines with different amounts of available memory
In a memory limited situation, mmapping will be substantially faster than reading directly into memory. Why?
lmdb¶
For more structured storage use the Lightning Memory-Mapped Database. https://lmdb.readthedocs.io/en/release/
(key,value) pairs of bytestrings
import lmdb
env = lmdb.open('db')
with env.begin(write=True) as txn:
txn.put(b'key1',b'123')
txn.put(b'key2',b'abc')
env = lmdb.open('db',readonly=True)
with env.begin() as txn:
print(txn.get(b'key1'))
b'123'
Going beyond raw bytes¶
import numpy as np
a = np.array([1.0,3.14,2])
env = lmdb.open('db')
with env.begin(write=True) as txn:
txn.put(b'key', a)
env = lmdb.open('db',readonly=True)
with env.begin() as txn:
buffer = txn.get(b'key')
buffer
b'\x00\x00\x00\x00\x00\x00\xf0?\x1f\x85\xebQ\xb8\x1e\t@\x00\x00\x00\x00\x00\x00\x00@'
newa = np.frombuffer(buffer,dtype=np.float64) # does NOT copy!
newa.base is buffer
True
newa[0] = 4
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/c_/pwm7n7_174724g8zkkqlpr3m0000gn/T/ipykernel_90836/3218751096.py in <module> ----> 1 newa[0] = 4 ValueError: assignment destination is read-only
Threads vs. Processs¶
import threading,time
cnt = [0]
def incrementCnt(cnt):
for i in range(1000000): # a million times
cnt[0] += 1
t1 = threading.Thread(target=incrementCnt,args=(cnt,))
t2 = threading.Thread(target=incrementCnt,args=(cnt,))
t1.start()
t2.start()
What do we expect when we print cnt?
%%html
<div id="mlthread1" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#mlthread1';
jQuery(divid).asker({
id: divid,
question: "What is cnt?",
answers: ['0','2','1000000','2000000',"I don't know"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
The Answer¶
import threading,time
cnt = [0]
def incrementCnt(cnt):
for i in range(1000000): # a million times
cnt[0] += 1
t1 = threading.Thread(target=incrementCnt,args=(cnt,))
t2 = threading.Thread(target=incrementCnt,args=(cnt,))
t1.start()
t2.start()
print(cnt) #what do we expect to print out?
time.sleep(1)
print(cnt)
time.sleep(1)
print(cnt)
[277570] [1182565] [1182565]
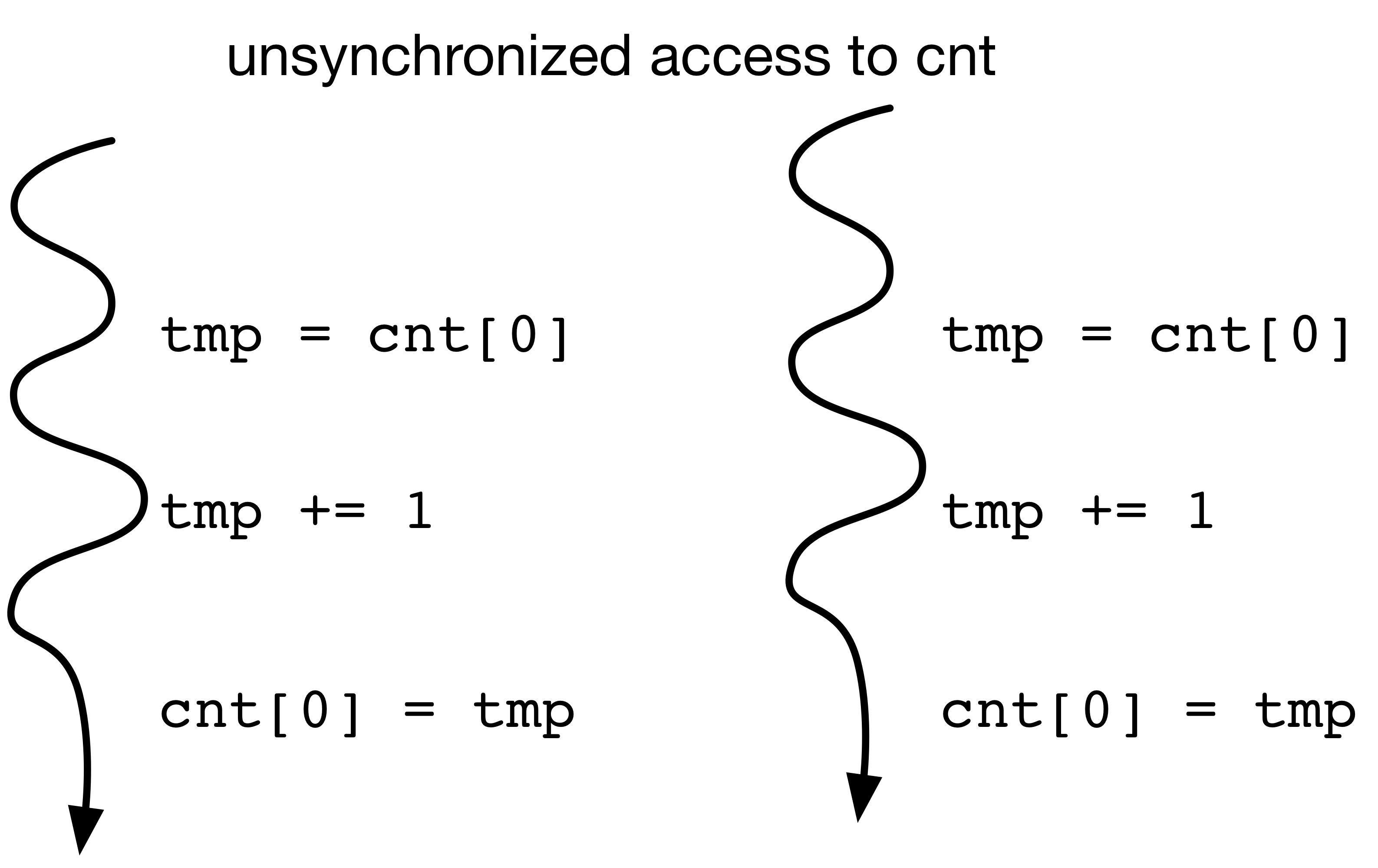
Threads vs. Processes¶
import multiprocess,time
cnt = [0]
p1 = multiprocess.Process(target=incrementCnt,args=(cnt,))
p2 = multiprocess.Process(target=incrementCnt,args=(cnt,))
p1.start()
p2.start()
#what do we expect when we print out cnt[0]?
%%html
<div id="mlproc1" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#mlproc1';
jQuery(divid).asker({
id: divid,
question: "What will print out?",
answers: ['0','2','1000000','2000000',"I don't know"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
The Answer¶
cnt = [0]
p1 = multiprocess.Process(target=incrementCnt,args=(cnt,))
p2 = multiprocess.Process(target=incrementCnt,args=(cnt,))
p1.start()
p2.start()
print(cnt[0])
time.sleep(3)
print(cnt[0])
0 0
Parallel Programming Concepts: Synchronization¶
Thread synchronization ensures that concurrent processes/threads do not simultaneously execute a critical section.
A critical section usually references a shared resource that must be accessed in sequence, like the cnt variable in the previous example.
Example: Lock¶
Can be acquired by exactly one thread (calling acquire twice from the same thread will hang). Must be released to be acquired by another thread. Basically, just wrap the critical section with an acquire-release pair.
Also: RLock, Condition, Semaphore, Mutex...¶
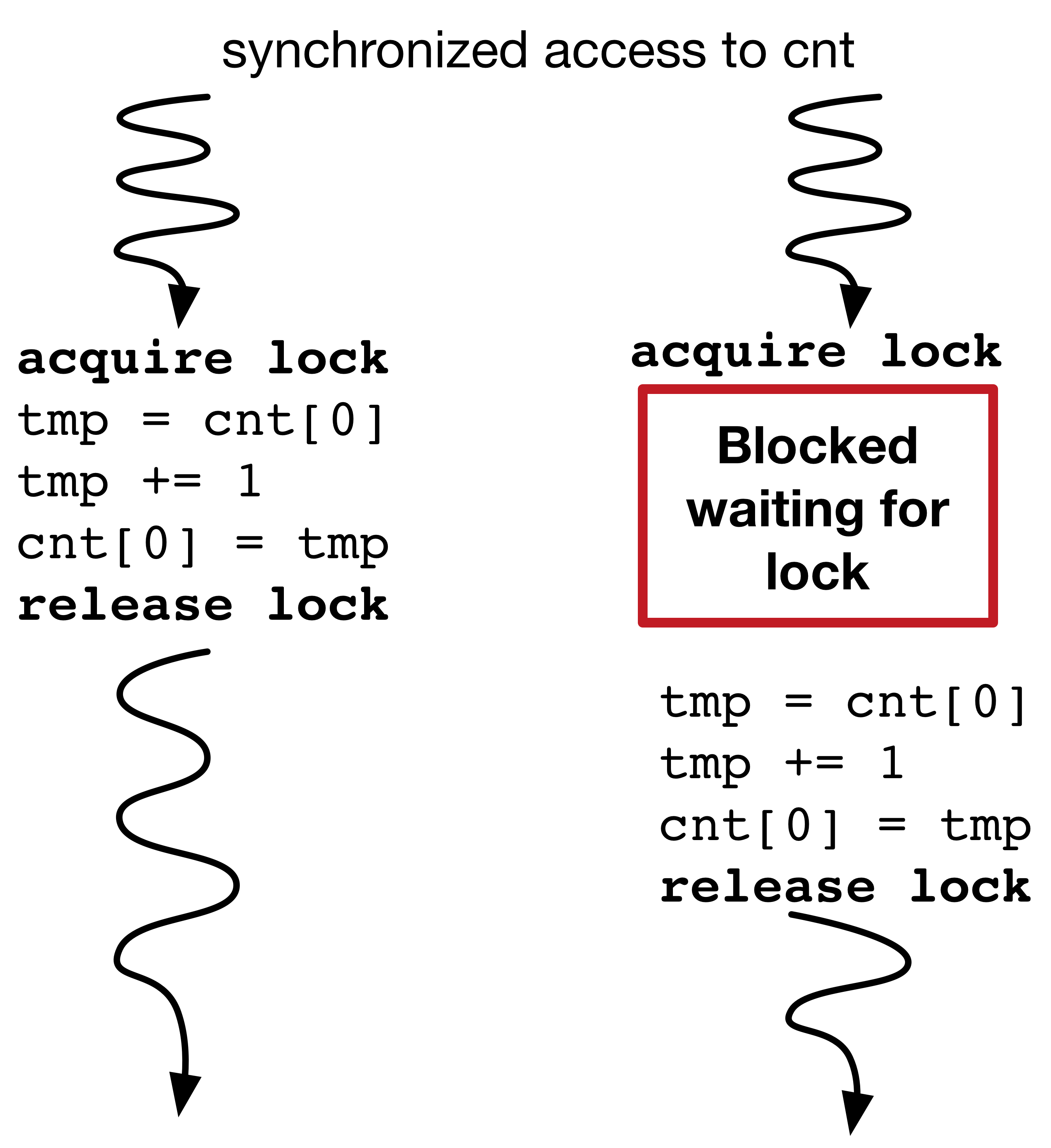
Lock Example¶
lock = threading.Lock()
def incrementCnt(cnt):
for i in range(1000000): # a million times
lock.acquire() #only one thread can acquire the lock at a time
cnt[0] += 1 #this is the CRITICAL SECTION
lock.release()
cnt = [0]
t1 = threading.Thread(target=incrementCnt,args=(cnt,))
t2 = threading.Thread(target=incrementCnt,args=(cnt,))
t1.start() #start launches the thread to run target with args
t2.start()
t1.join()
t2.join()
print(cnt[0])
2000000
%%html
<div id="mlsync1" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#mlsync1';
jQuery(divid).asker({
id: divid,
question: "What is synchronization good for?",
answers: ['Ensuring correctness','Improving single-thread performance','Improving multi-thread performance (scalability)','All of the above'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Parallel Programming Concepts: Communication¶
Threads can communicate through their shared address space using locks to protect sensitive state (e.g., ensure data is updated atomically). However, using simpler, less flexible communication protocols makes it easier to write correct code.
Queue¶
Provides one-way communication between many threads/processes (producer-consumer)
Pipe/Socket¶
Provides two-way communication between two threads/processes
These are examples of communication with message passing.
Queue Example¶
def dowork(inQ, outQ):
val = inQ.get()
outQ.put(val*val)
inQ = multiprocess.Queue()
outQ = multiprocess.Queue()
pool = multiprocess.Pool(4, dowork, (inQ, outQ))
inQ.put(4)
outQ.get()
16
Pipe Example¶
import multiprocess
def chatty(conn): #this takes a Connection object representing one end of a pipe
msg = conn.recv()
conn.send("you sent me "+msg)
(c1,c2) = multiprocess.Pipe()
p1 = multiprocess.Process(target=chatty,args=(c2,))
p1.start()
c1.send("Hello!")
result = c1.recv()
p1.join()
print(result)
you sent me Hello!
Distributed Systems¶
A bunch of computer networked together working towards a common purpose.
- no global clock
- communicate via message passing
- components (computers) run independently and concurrently
- components fail independently
Examples¶
cloud computing - commodity components connected with a commodity network where the whole system is controlled by one entity, computers arranged in clusters
grid computing - highly heterogeneous network of geographically dispersed computers working on independent subcomponents of a larger problem: volunteer computing
world community grid: OpenZika
the Internet, the Web, BitTorrent, BitCoin, your car, MMORPGs
Challenges¶
How is work partitioned into parallel tasks?
How are tasks assigned?
- where?
- when?
How do nodes communicate?
How do tasks synchronize?
How does the system scale?
- more jobs
- more resources
- more data
How is failure dealt with?
- total node failure
- slow node
- broken network connection
- storage failure/incorrect data
Privacy, Security, Trustworthiness (not going to worry about these)