%%html
<script src="https://bits.csb.pitt.edu/asker.js/lib/asker.js"></script>
<style>
.reveal .highlight pre { font-size: 100%}
.reveal .slides>section>section.present { max-height: 100%; overflow-y: auto;}
</style><script>
require(['https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.2.2/Chart.js'], function(Ch){
Chart = Ch;
});
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
//the callback is provided a canvas object and data
var chartmaker = function(canvas, labels, data) {
var ctx = $(canvas).get(0).getContext("2d");
var dataset = {labels: labels,
datasets:[{
data: data,
backgroundColor: "rgba(150,64,150,0.5)",
fillColor: "rgba(150,64,150,0.8)",
}]};
var myBarChart = new Chart(ctx,{type:'bar',data:dataset,options:{legend: {display:false},
scales: {
yAxes: [{
ticks: {
min: 0,
}
}]}}});
};
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
What is machine learning?¶
Machine learning is a subfield of computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. --Wikipedia
Creating useful and/or predictive computational models from data --dkoes
Unsupervised Learning¶
Construct a model from unlabeled data. That is, discover an underlying structure in the data.
- clustering
- Principal Components Analysis (PCA)
- Latent variable methods
- Expectation-maximization
- Self-organizing map
import numpy as np
import scipy.cluster.vq as vq #vq: vector quantization
import matplotlib.pylab as plt
%matplotlib inline
randpts = np.vstack((np.random.randn(100,2)/(4,1),(np.random.randn(100,2)+(1,0))/(1,4)))
(means,clusters) = vq.kmeans2(randpts,4)
plt.scatter(randpts[:,0],randpts[:,1],c=clusters)
plt.plot(means[:,0],means[:,1],'*',ms=20);

Supervised Learning¶
Create a model from labeled data. The data consists of a set of examples where each example has a number of features X and a label y.
Our assumption is that the label is a function of the features:
$$y = f(X)$$
And our goal is to determine what f is.
We want a model/estimator/classifier that accurately predicts y given an X.
Labels¶
There are two main types of supervised learning depending on the type of label.
Classification¶
The label is one of a limited number of classes. Most commonly it is a binary label.
- Will it rain tomorrow?
- Is the protein overexpressed?
- Do the cells die?
Regression¶
The label is a continuous value.
- How much precipitation will there be tomorrow?
- What is the expression level of the protein?
- What percent of the cells died?
Features¶
The features, X, are what make each example distinct. Ideally they contain enough information to predict y. The choice of features is critical and problem-specific.
There are three main three main types:
- Binary - zero or one
- Nominal - one of a limited number of values
- low, medium, high
- nucleus, vacuole, cytoplasm
- Numerical
Not all classifiers can handle all three types, but we can inter-convert.
How?
Example¶
Let's use chemical fingerprints as features!
!wget http://mscbio2025.csb.pitt.edu/files/er.smi
--2023-06-28 22:35:04-- http://mscbio2025.csb.pitt.edu/files/er.smi Resolving mscbio2025.csb.pitt.edu (mscbio2025.csb.pitt.edu)... 136.142.4.139 Connecting to mscbio2025.csb.pitt.edu (mscbio2025.csb.pitt.edu)|136.142.4.139|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 20022 (20K) [application/smil+xml] Saving to: ‘er.smi.4’ er.smi.4 100%[===================>] 19.55K --.-KB/s in 0.006s 2023-06-28 22:35:04 (3.21 MB/s) - ‘er.smi.4’ saved [20022/20022]
!head er.smi
from openbabel import pybel
yvals = []
fps = []
for mol in pybel.readfile('smi','er.smi'):
yvals.append(float(mol.title))
fpbits = mol.calcfp().bits
fp = np.zeros(1024)
fp[fpbits] = 1
fps.append(fp)
X = np.array(fps)
y = np.array(yvals)
X.shape
(387, 1024)
list(X[0])
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ...]
The y-values, taken from the second column of the smiles file, are the logS solubility (I think).
plt.hist(y);

%%html
<div id="classtypehs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#classtypehs';
jQuery(divid).asker({
id: divid,
question: "What sort of problem is this??",
answers: ['Classification','Regression','Unsupervised'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
sklearn¶
scikit-learn provides a complete set machine learning tools.
- Classification
- Regression
- Clustering
- Dimensionality reduction
- Model selection and evaluation
- Preprocessing
import sklearn
Linear Model¶
One of the simplest models is a linear regression, where the goal is to find weights w to minimize: $$\sum(Xw - y)^2$$
 |
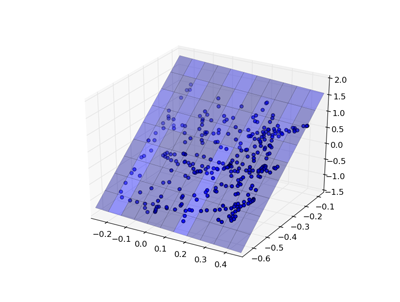 |
%%html
<div id="wshapehs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#wshapehs';
jQuery(divid).asker({
id: divid,
question: "What is the shape of w?",
answers: ['387','1024','(378,1024)','(1024,387)',"I've never taken matrix algebra"],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Linear Model¶
sklearn has a uniform interface for all its models:
from sklearn import linear_model
model = linear_model.LinearRegression() # create the model
model.fit(X,y) # fit the model to the data
p = model.predict(X) # make predictions with the model
plt.scatter(y,p);

Let's reframe this is a classification problem for illustrative purposes...
ylabel = y > 0
plabel = p > 0
Evaluating Predictions¶
There are a number of ways to evaluate how good a prediction is.
- TP true positive, a correctly predicted positive example
- TN true negatie, a correctly predicted negative example
- FP false positive, a negative example incorrectly predicted as positive
- FN false negative, a positive example incorrectly predicted as negative
- P total number of positives (TP + FN)
- N total number of negatives (TN + FP)
Accuracy: $\frac{TP+TN}{P+N}$
from sklearn.metrics import * #pull in accuracy score, amount other things
accuracy_score(ylabel, plabel)
0.9896640826873385
Confusion matrix¶
The confusion matrix compares the predicted class to the actual class.
print(confusion_matrix(ylabel,plabel))
[[305 1] [ 3 78]]
This corresponds to:
print(np.array([['TN', 'FP'],['FN','TP']]))
[['TN' 'FP'] ['FN' 'TP']]
Other measures¶
Precision. Of those predicted true, how may are accurate? $\frac{TP}{TP+FP}$
Recall (true positive rate). How many of the true examples were retrieved? $\frac{TP}{P}$
F1 Score. The geometric mean of precision and recall. $\frac{2TP}{2TP+FP+FN}$
print(classification_report(ylabel,plabel))
precision recall f1-score support
False 0.99 1.00 0.99 306
True 0.99 0.96 0.97 81
accuracy 0.99 387
macro avg 0.99 0.98 0.98 387
weighted avg 0.99 0.99 0.99 387
%%html
<div id="confqhs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#confqhs';
jQuery(divid).asker({
id: divid,
question: "What would the recall be if our classifer predicted everything as true?",
answers: ['0','81/306','0.5','1.0'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
ROC Curves¶
The previous metrics work on classification results (yes or no). Many models are capable of producing scores or probabilities (recall we had to round our results). The classification performance then depends on what score threshold is chosen to distinguish the two classes.
ROC curves plot the false positive rate and true positive rate as this treshold is changed.
fpr, tpr, thresholds = roc_curve(ylabel, p) #not using rounded values
plt.plot(fpr,tpr,linewidth=4,clip_on=False)
plt.xlabel("FPR"); plt.ylabel("TPR")
plt.gca().set_aspect('equal')
plt.ylim(0,1); plt.xlim(0,1); plt.show()

AUC¶
The area under the ROC curve (AUC) has a statistical meaning. It is equal to the probability that the classifier will rank a randomly chosen positive example higher than a randomly chosen negative example.
An AUC of one is perfect prediction.
An AUC of 0.5 is the same as random.
np.random.shuffle(p)
fpr, tpr, thresholds = roc_curve(ylabel, p)
plt.plot(fpr,tpr,linewidth=3); plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1)
plt.gca().set_aspect('equal')
print(roc_auc_score(ylabel,p))
0.46558541111918017

Correct Model Evaluation¶
We are most interested in generalization error: the ability of the model to predict new data that was not part of the training set.
We have been evaluating how well our model can fit the training data. This is usually irrelevant.
In order to assess the predictiveness of the model, we must use it to predict data it has not been trained on.

%%html
<div id="crossqhs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#crossqhs';
jQuery(divid).asker({
id: divid,
question: "In 5-fold cross validation, on average, how many times will a given example be in the training set?",
answers: ['0','1','2.5','4','5'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Cross Validation¶
sklearn implement a number of cross validation variants. They provide a way to generate test/train sets.
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
accuracies = []; rocs = []
for train,test in kf.split(X): # these are arrays of indices
model = linear_model.LinearRegression()
model.fit(X[train],y[train]) #slice out the training folds
p = model.predict(X[test]) #slice out the test fold
accuracies.append(accuracy_score(ylabel[test],p > 0))
fpr, tpr, thresholds = roc_curve(ylabel[test], p)
rocs.append( (fpr,tpr, roc_auc_score(ylabel[test], p)))
print(accuracies)
print("Average accuracy:",np.mean(accuracies))
[0.6153846153846154, 0.7692307692307693, 0.6753246753246753, 0.8311688311688312, 0.7402597402597403] Average accuracy: 0.7262737262737263
np.count_nonzero(ylabel==0)/float(len(ylabel))
0.7906976744186046
for roc in rocs:
plt.plot(roc[0],roc[1],label="AUC %.2f" %roc[2]);
plt.gca().set_aspect('equal')
plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1); plt.legend(loc='best'); plt.show()

%%html
<div id="howgoodhs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#howgoodhs';
jQuery(divid).asker({
id: divid,
question: "How good is the predictiveness of our model?",
answers: ['A','B','C','D'],
extra: ['Still Perfect','Not perfect, but still good','Not great, but better than random','Horrible'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Generalization Error¶
There are several sources of generalization error:
- overfitting - using artifacts of the data to make predictions
- our data set has 387 examples and 1024 features
- insufficient data - not enough or not the right kind
- inappropriate model - isn't capable of representing reality
A large different between cross-validation performance and fit (test-on-train) performance indicates overfitting.
One way to reduce overfitting is to reduce the number of features used for training (this is called feature selection).
LASSO¶
Lasso is a modified form of linear regression that includes a regularization parameter $\alpha$ $$\sum(Xw - y)^2 + \alpha\sum|w|$$
The higher the value of $\alpha$, the greater the penalty for having non-zero weights. This has the effect of driving weights to zero and selecting fewer features for the model.
kf = KFold(n_splits=5)
accuracies = []; rocs = []
for train,test in kf.split(X): # these are arrays of indices
model = linear_model.Lasso(alpha=0.005)
model.fit(X[train],y[train]) #slice out the training folds
p = model.predict(X[test]) #slice out the test fold
accuracies.append(accuracy_score(ylabel[test],p > 0))
fpr, tpr, thresholds = roc_curve(ylabel[test], p)
rocs.append( (fpr,tpr, roc_auc_score(ylabel[test],p)))
print(accuracies)
print("Average accuracy:",np.mean(accuracies))
[0.9743589743589743, 0.9871794871794872, 0.974025974025974, 0.935064935064935, 1.0] Average accuracy: 0.974125874125874
for roc in rocs:
plt.plot(roc[0],roc[1],label="AUC %.2f" %roc[2]);
plt.gca().set_aspect('equal')
plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1); plt.legend(loc='best'); plt.show()

Lasso vs. LinearRegression¶
linmodel = linear_model.LinearRegression()
linmodel.fit(X,y)
lassomodel = linear_model.Lasso(alpha=0.005)
lassomodel.fit(X,y);
The Lasso model is much simpler
print("Nonzero coefficients in linear:",np.count_nonzero(linmodel.coef_))
print("Nonzero coefficients in LASSO:",np.count_nonzero(lassomodel.coef_))
Nonzero coefficients in linear: 881 Nonzero coefficients in LASSO: 64
Model Parameter Optimization¶
Most classifiers have parameters, like $\alpha$ in Lasso, that can be set to change the classification behavior.
A key part of training a model is figuring out what parameters to use.
This is typically done by a brute-force grid search (i.e., try a bunch of values and see which ones work)
from sklearn import model_selection
#setup grid search with default 3-fold CV and scoring
searcher = model_selection.GridSearchCV(linear_model.Lasso(max_iter=10000), {'alpha': [0.001,0.005,0.01,0.1]})
searcher.fit(X,y)
searcher.best_params_
{'alpha': 0.005}
Model specific optimization¶
Some classifiers (mostly linear models) can identify optimal parameters more efficiently and have a "CV" version that automatically determines the best parameters.
lassomodel = linear_model.LassoCV(n_jobs=8,max_iter=10000)
lassomodel.fit(X,y)
LassoCV(max_iter=10000, n_jobs=8)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LassoCV(max_iter=10000, n_jobs=8)
lassomodel.alpha_
0.0045520394784971056
Support Vector Machine (SVM)¶
A support vector machine is orthogonal to a linear model - it attempts to find a plane that separates the classes of data with the maximum margin.

There are two key parameters in an SVM: the kernel and the penalty term (and some kernels may have additional parameters).
SVM Kernels¶
A kernel function, $\phi$, is a transformation of the input data that let's us apply SVM (linear separation) to problems that are not linearly separable.


Training SVM¶
We can get both the predictions (0 or 1) from the SVM as well as probabilities, a confidence in how accurate the predictions are. We use the probabilities to compute the ROC curve.
from sklearn import svm
kf = KFold(n_splits=5)
accuracies = []; rocs = []
for train,test in kf.split(X): # these are arrays of indices
model = svm.SVC(probability=True)
model.fit(X[train],ylabel[train]) #slice out the training folds
p = model.predict(X[test]) # prediction (0 or 1)
probs = model.predict_proba(X[test])[:,1] #probability of being 1
accuracies.append(accuracy_score(ylabel[test],p))
fpr, tpr, thresholds = roc_curve(ylabel[test], probs)
rocs.append( (fpr,tpr, roc_auc_score(ylabel[test],probs)))
Training SVM¶
print(accuracies)
print("Average accuracy:",np.mean(accuracies))
[0.9743589743589743, 0.9615384615384616, 0.974025974025974, 0.935064935064935, 0.974025974025974] Average accuracy: 0.9638028638028638
for roc in rocs:
plt.plot(roc[0],roc[1],label="AUC %.2f" %roc[2]);
plt.gca().set_aspect('equal')
plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1); plt.legend(loc='best'); plt.show()

Training SVM¶
from sklearn import model_selection
searcher = model_selection.GridSearchCV(svm.SVC(), {'kernel': ['linear','rbf'],'C': [1,10,100,1000]},scoring='roc_auc',n_jobs=-1)
searcher.fit(X,ylabel)
GridSearchCV(estimator=SVC(), n_jobs=-1,
param_grid={'C': [1, 10, 100, 1000], 'kernel': ['linear', 'rbf']},
scoring='roc_auc')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=SVC(), n_jobs=-1,
param_grid={'C': [1, 10, 100, 1000], 'kernel': ['linear', 'rbf']},
scoring='roc_auc')SVC()
SVC()
print("Best AUC:",searcher.best_score_)
print("Parameters",searcher.best_params_)
Best AUC: 0.9915256478053939
Parameters {'C': 1, 'kernel': 'linear'}
Nearest Neighbors (NN)¶
Nearest Neighbors models classify new points based on the values of the closest points in the training set.
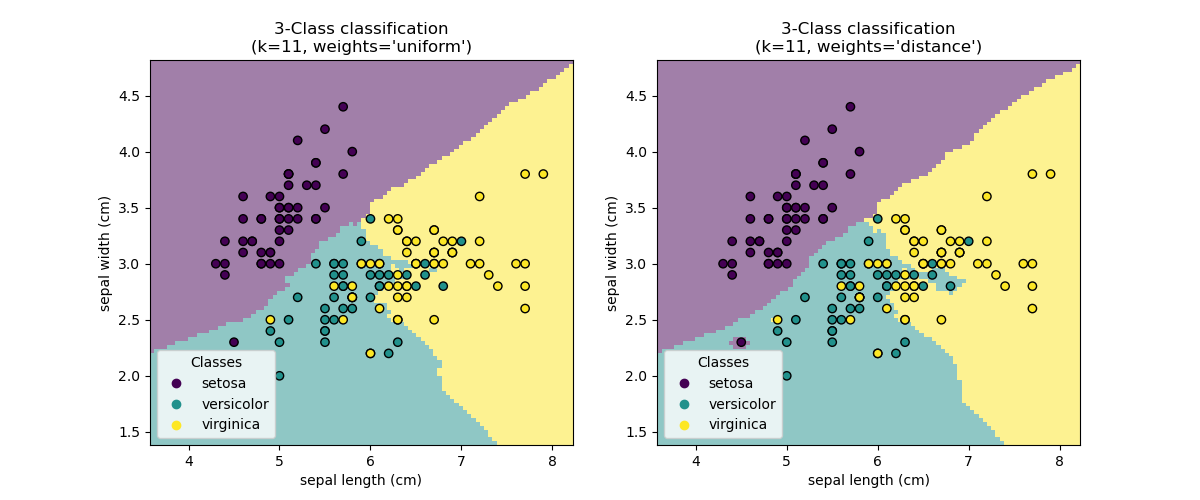
The main parameter is $k$, the number of neighbors to consider, and the method of combining the neighbor results.
Training NN¶
from sklearn import neighbors
kf = KFold(n_splits=5)
accuracies = []; rocs = []
for train,test in kf.split(X): # these are arrays of indices
model = neighbors.KNeighborsClassifier() # defaults to k=5
model.fit(X[train],ylabel[train]) #slice out the training folds
p = model.predict(X[test]) # prediction (0 or 1)
probs = model.predict_proba(X[test])[:,1] #probability of being 1
accuracies.append(accuracy_score(ylabel[test],p))
fpr, tpr, thresholds = roc_curve(ylabel[test], probs)
rocs.append( (fpr,tpr, roc_auc_score(ylabel[test],probs)))
Training NN¶
print(accuracies)
print("Average accuracy:",np.mean(accuracies))
[0.9615384615384616, 0.9615384615384616, 0.974025974025974, 0.935064935064935, 1.0] Average accuracy: 0.9664335664335664
for roc in rocs:
plt.plot(roc[0],roc[1],label="AUC %.2f" %roc[2]);
plt.gca().set_aspect('equal')
plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1); plt.legend(loc='best'); plt.show()

%%html
<div id="knnqhs" style="width: 500px"></div>
<script>
$('head').append('<link rel="stylesheet" href="https://bits.csb.pitt.edu/asker.js/themes/asker.default.css" />');
var divid = '#knnqhs';
jQuery(divid).asker({
id: divid,
question: "What could <b>not</b> be a valid probability from the previous k-nn (k=5) model?",
answers: ['0','.5','.6','1'],
server: "https://bits.csb.pitt.edu/asker.js/example/asker.cgi",
charter: chartmaker})
$(".jp-InputArea .o:contains(html)").closest('.jp-InputArea').hide();
</script>
Training NN¶
searcher = model_selection.GridSearchCV(neighbors.KNeighborsClassifier(), \
{'n_neighbors': [1,2,3,4,5,10]},scoring='roc_auc',n_jobs=-1)
searcher.fit(X,ylabel);
print("Best AUC:",searcher.best_score_)
print("Parameters",searcher.best_params_)
Best AUC: 0.9840936751485364
Parameters {'n_neighbors': 5}
Decision Trees¶
A decision tree is a tree where each node make a decision based on the value of a single feature. At the bottom of the tree is the classification that results from all those decisions.

Significant model parameters include the depth of the tree and how features and splits are determined.
Random Forest¶
A bunch of decision trees trained on different sub-samples of the data.
The vote (or are averaged).
Training a Decision Tree¶
from sklearn import tree
kf = KFold(n_splits=5)
accuracies = []; rocs = []
for train,test in kf.split(X): # these are arrays of indices
model = tree.DecisionTreeClassifier()
model.fit(X[train],ylabel[train]) #slice out the training folds
p = model.predict(X[test]) # prediction (0 or 1)
probs = model.predict_proba(X[test])[:,1] #probability of being 1
accuracies.append(accuracy_score(ylabel[test],p))
fpr, tpr, thresholds = roc_curve(ylabel[test], probs)
rocs.append( (fpr,tpr, roc_auc_score(ylabel[test],probs)))
Training a Decision Tree¶
print(accuracies)
print("Average accuracy:",np.mean(accuracies))
[0.9743589743589743, 0.9487179487179487, 0.987012987012987, 0.961038961038961, 1.0] Average accuracy: 0.9742257742257742
for roc in rocs:
plt.plot(roc[0],roc[1],label="AUC %.2f" %roc[2]);
plt.gca().set_aspect('equal')
plt.xlabel("FPR"); plt.ylabel("TPR"); plt.ylim(0,1); plt.xlim(0,1); plt.legend(loc='best'); plt.show()

set(probs)
{0.0, 0.5, 1.0}
Training a Decision Tree¶
searcher = model_selection.GridSearchCV(tree.DecisionTreeClassifier(), \
{'max_depth': [1,2,3,4,5,10]},scoring='roc_auc',n_jobs=-1)
searcher.fit(X,ylabel);
print("Best AUC:",searcher.best_score_)
print("Parameters",searcher.best_params_)
Best AUC: 0.9771942171897845
Parameters {'max_depth': 5}
Regression¶
Regression in sklearn is pretty much the same as classification, but you use a score appropriate for regression (e.g., squared error or correlation).
Project¶
Pick a model and train it to predict the actual y values (regression).
!wget http://bits.csb.pitt.edu/files/mldata.npz
--2022-07-05 08:29:17-- http://bits.csb.pitt.edu/files/mldata.npz Resolving bits.csb.pitt.edu (bits.csb.pitt.edu)... 136.142.4.139 Connecting to bits.csb.pitt.edu (bits.csb.pitt.edu)|136.142.4.139|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 3173890 (3.0M) Saving to: ‘mldata.npz’ mldata.npz 100%[===================>] 3.03M 6.07MB/s in 0.5s 2022-07-05 08:29:17 (6.07 MB/s) - ‘mldata.npz’ saved [3173890/3173890]
import numpy as np
data = np.load('mldata.npz')
X = data['X']
y = data['y']